"This GAN Page Does Not Exist" Making-of - Part 1: The GAN That Never Was
02 Jun 2019
This article is part of my series “This GAN Page Does Not Exist Making-Of”. It is recommended to read the previous article if you haven’t yet.
In the previous article I described how I had the idea for a meta “This GAN Page Does Not Exist” page about GAN (Generative Adversarial Network). Here I will describe my first attempt, which I did not carry on as I eventually found a better way to achieve the goal; I am only recording this for informational purpose about using StyleGAN.
The Concept
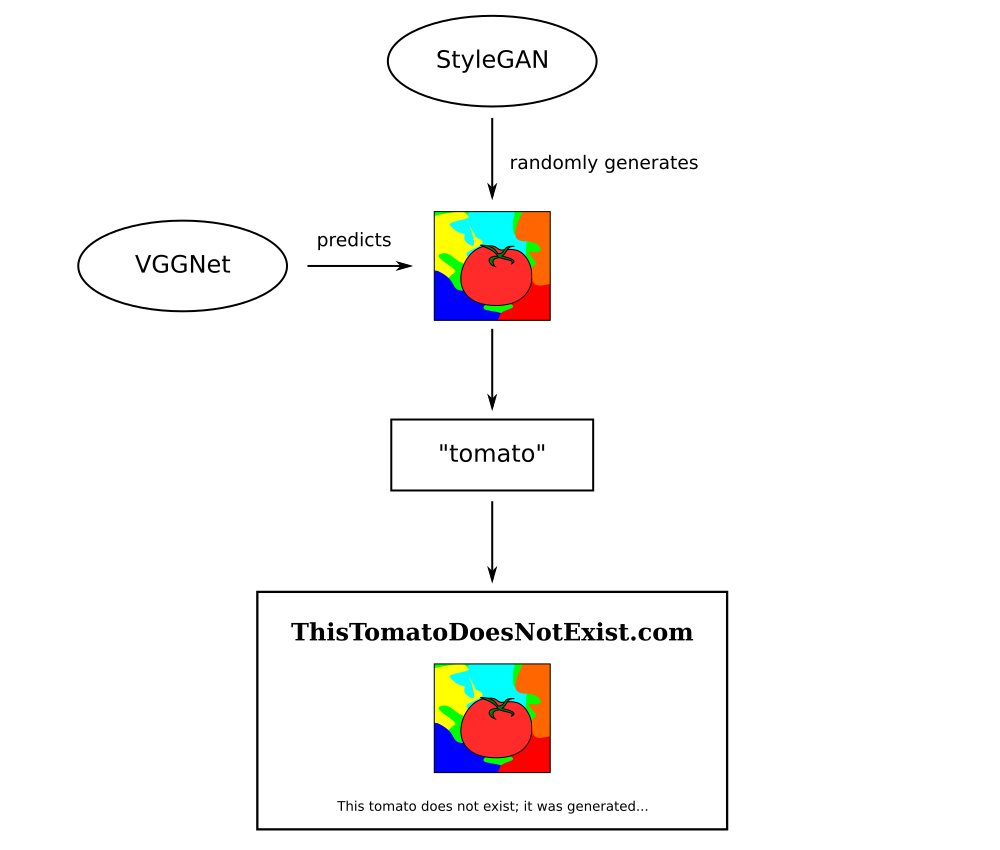
As described before, the idea was this: a simple Web page where, every time the user refreshes, she is greeted with “This X Does Not Exist” (with “X” being a random type of object) and a GAN-generated picture of said X, with a small blurb beneath.
How could this be done? If I wanted to stay true to the original concept, I would have a neural network generate an entire Web page in HTML, complete with the corresponding image, too. The problems were:
- Although it seems to be possible to generate HTML content with neural networks, it demands a fair amount of resources and training data that I found overkill for what I was trying to achieve.
- I was far from having enough training data to generate that specific kind of content.
- I felt that would be using intensive resources for generating relatively small content.
Not to mention the complicated neural network architecture I would have to devise in order to get the generated HTML to be consistent with what the generated image would be supposed to represent.
I then had the idea to “cheat” by doing it the other way around, somehow: a GAN would generate a random image, then the Web page’s HTML content would be generated from the image.
How the image would be generated? By training StyleGAN other a subset of ImageNet, an online image database consisting of millions of images of all kinds, annotated with thousands of categories. This database is often used for computer vision purposes, most notably the ImageNet Large Scale Visual Recognition Challenge. I figured, training StyleGAN over this database would produce “random” images of “random” things.
Once the images were generated, I thought of using one of the aforementioned image recognition networks, such as ResNet or VGGNet, use the network’s predictions to get the “X” in “This X Does Not Exist” and, from there, generate the rest of the website with a simple template.
This basic diagram explains the original idea:
Getting the training data
First, I needed to train StyleGAN over the ImageNet database. The original database consists of +14 million URLs pointing to random pictures across the Web – which is huge! I decided that I only needed a subset of these URLs to do the training.
I first downloaded the ~1GB ImageNet file containing the URLs, which can be found on the ImageNet website. In a Unix shell, executing the following command:
$ wc -l fall11_urls.txt
14197122gives the total number of URLs in the file.
Lines in the file follow this format:
<category_id> <url>
Example:
123456_789 http://example.com/image.jpg
Therefore, with the following Python script we can extract random lines from the file:
import numpy as np
NUMBER_OF_LINES = 14197122 # total number of lines
NUMBER_OF_EXAMPLES = 35000 # how many lines we want to extract
URLS_FILENAME = 'fall11_urls.txt'
# get N random unique numbers
image_ids = np.random.choice(range(NUMBER_OF_LINES), NUMBER_OF_EXAMPLES, replace=False)
urls = []
with open(URLS_FILENAME, 'rb') as input_file:
image_id = 0
line = input_file.readline()
while line and len(urls) < NUMBER_OF_EXAMPLES:
if image_id in image_ids:
# retrieve URL from line
line = line.decode('utf8').strip()
urls.append(line.split(maxsplit=1)[-1])
image_id += 1
line = input_file.readline()
print("Got %d URLs" % len(urls))
with open('image-net-%d-urls.txt' % NUMBER_OF_EXAMPLES, 'w', encoding='utf8') as output_file:
output_file.write("\n".join(urls))With that list of random URLs, we can download the images one by one using a tool like wget. Keep in mind that many referenced pictures seem unavailable, so you have to check if the downloaded pictures are valid.
Training StyleGAN
As said in the previous article, StyleGAN is an open-source project and can be used by anyone. However, while there is documentation about the script that generates images using an already-trained network, the script that trains a network from scratch is much less thoroughly described.
I’ll have to give credit to Woctezuma and his project to generate Steam banners using StyleGAN and the Google Colab platform, which I used as reference to train my own StyleGAN network. I also recommend reading this article by Gwern Branwen for more specific information about this topic.
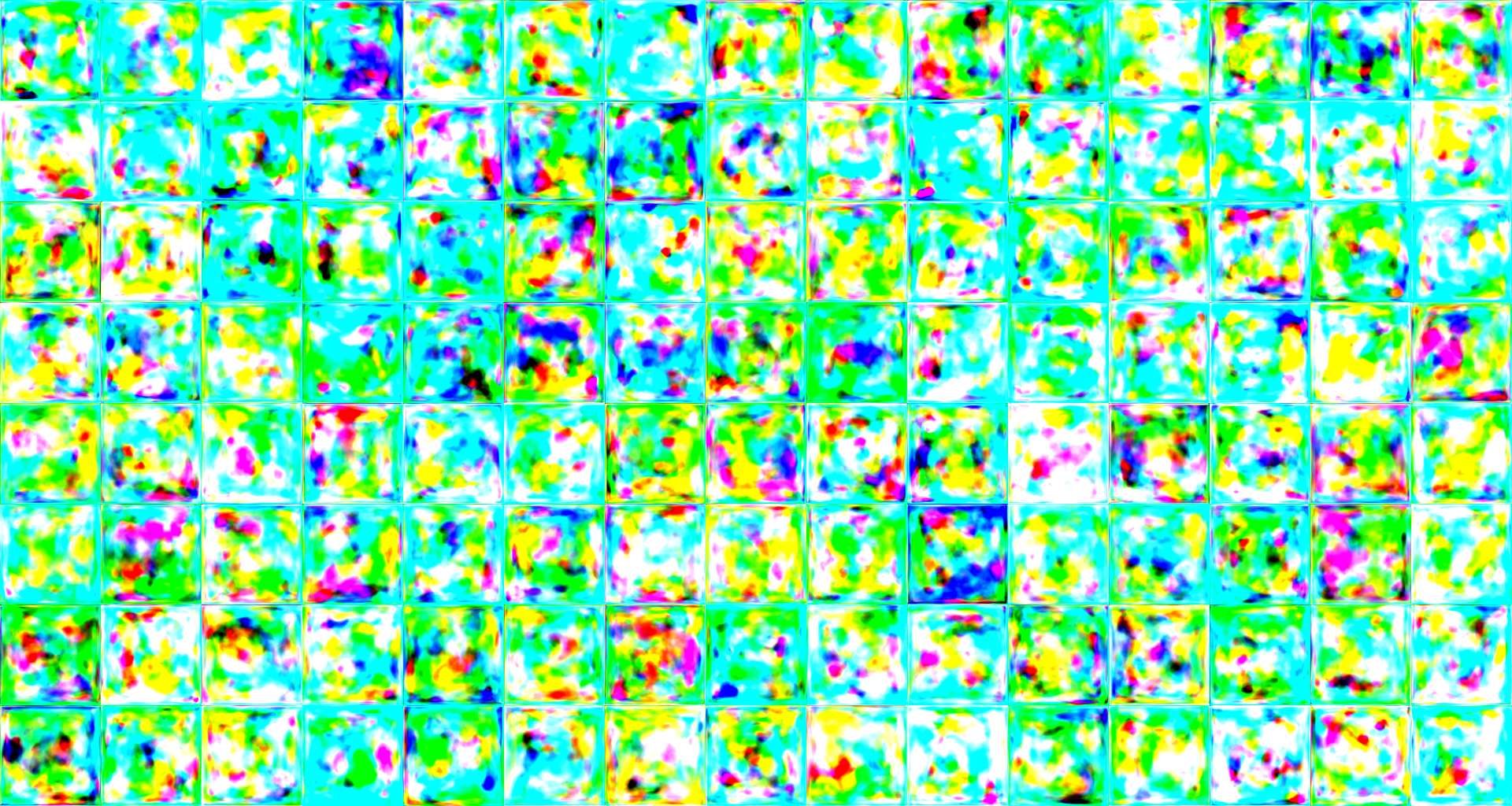
Training StyleGAN on the retrieved pictures from ImageNet, after these were all processed and rescaled to a power-of-two size of 128x128 pixels, initially it only produced random noise:
This was the output result after only 140 iterations:

Finally, after 1402 iterations:

Several hours had passed and the results weren’t still too convincing. However, there was visible diversity in the pictures, and blob-like shapes began to appear, which is already a positive thing as it is better than just random noise.
Conclusion
It was around this time, while looking for more information about generative networks, that I stumbled upon the discovery of BigGAN which would be decisive in the direction the project would take. But that will be for the next article…